 1 week ago
23
1 week ago
23

I love investigating websites. I wrote a chapter about it for the most recent edition of the Verification Handbook and I’m always looking for new tools and methods to connect sites together, identify owners, and to analyze site content, infrastructure, and behavior.
The Information Laundromat is open source and available on the Alliance for Securing Democracy’s GitHub account.The Information Laundromat is one of the newest and most interesting free website analysis tools I’ve come across. Developed by the George Marshall Fund’s Alliance For Securing Democracy (ASD), it can analyze content and metadata. ASD, with researchers at the University of Amsterdam and the Institute for Strategic Dialogue, used it in their recent report, “The Russian Propaganda Nesting Doll: How RT is Layered into the Digital Information Environment.”
The Information Laundromat can analyze two elements: the content posted to a site and the metadata used to build and run it. Here’s a rundown of how it works, based on initial testing by me and an interview with Peter Benzoni, the tool’s developer.
Peter told me that the Information Laundromat works best for lead generation: “It’s not supposed to automate your investigation.” The Information Laundromat is open source and available on the ASD’s GitHub account.
Content Similarity Analysis

Image: Screenshot, Digital Investigations
This tool analyzes a link, title, or snippet of text to identify other web properties with similar or identical content. It was useful in the ASD investigation because they wanted to see which sites consistently copied from Russia Today (RT), the Russian state broadcaster. They were able to identify sites that consistently reprinted RT content, and which played a role helping push RT’s narratives across the web, laundering its narratives, according to the research.
How It Works
- Enter the URL, title, or snippet of text you want to check.
- The system looks across search engines, the Copyscape plagiarism checker tool, and the GDELT database to analyze and rank the similarity of your source content and other sites.
- A results page sorts sites by the percentage of similar content to your original source.
I ran a sample search with a URL that I knew was a near carbon copy of a news article published elsewhere. The Information Laundromat correctly identified the original source of the text, giving it a 97% similarity score.

Image: Screenshot, Digital Investigations
The tool also highlights what it doesn’t do,
Content Similarity Search attempts to find similar articles or text across the open web. It does not provide evidence of where that text originated or any relationship between two entities posting two similar texts. Determination of a given text’s provenance is outside the scope of this tool.
If you get a lot of results, Peter suggested “downloading everything into as an Excel and looking through it on your own a little bit with a pivot table.”
Sites with 70% or higher similarity rating or higher are likely to be most of interest, according to Peter. The tool also has a batch upload option if you register on the site.
Metadata Similarity Analysis

Image: Screenshot, Digital Investigations
The Information Laundromat’s metadata similarity tool works best when you have a set of sites you want to analyze. It’s possible, but less effective, to use it to analyze a single site.
How It Works
- Enter a set of domains you want to analyze for shared connections.
- The tool scans each domain, including infrastructure such as IP addresses and source code, to extract unique indicators and to determine if there’s overlap between domains. It flags direct matches for IP addresses and it also highlights if sites are hosted in the same IP range, which is a weaker connection but still potentially of note. Along with looking for unique advertising and analytics codes, the tool scans a site’s CSS file to look for similarities. Peter told me that “it has to be greater than 90% similar CSS classes” for the tool to flag it as notable. (View the tool’s full list of website indicators here.)
- The metadata page sorts the results into two sections.
- The first table lists which indicators are present on each site.
- The second table identifies shared indicators across sites.
- The tool also sorts results in each table according to the relative strength of each indicator. (I explain more in the final section of this post.)
“The idea to try and draw out anything that you can tell about the sites that you might use to link to sites together,” Peter told me.
If you’re not familiar with the method of linking sites together via analytics and ad codes, you can read this basic guide and this recent post from me (read the guide first!). The Information Laundromat’s metadata module is most useful if you’re familiar with website infrastructure such as IP addresses and if you understand how to connect sites together using indicators. The risk in using this tool comes if you don’t understand the relative strengths and weaknesses of each indicator and connection. (More on that below.)
Peter said the metadata analysis tool is a great starting point for finding connections between a set of sites.
“If you have a set of sites and you would like to get a sense of the potential overlap, then this is a good way to do a quick snapshot of that, as opposed to running them manually in a bunch of other tools,” he said.
I agree that it’s potentially a good starting point if you have a set of sites you think may have connections. The Information Laundromat will give a useful overview of potential connections. Then you can take those and do a deeper dive using tools such as DNSlytics, BuiltWith, SpyOnWeb, and your favorite passive DNS platform.
While the tool works best with a group of domains, you can run a metadata search with a single URL. This is useful if you’d like the system to extract indicators such as analytics codes for you to easily search in places like DNSlytics. You can also see if the URL shares any indicators with the set of roughly 10,000 domains stored in the Information Laundromat database. The tool’s about page lists the sources.
- EU vs Disinfo’s Database.
- Research from partner and related organizations, such as the Institute for Strategic Dialogue’s (ISD) report on RT Mirror Sites.
- Known state media sites.
- Lists of unreliable sources, pink slime sites, and faux local news sites.
- Wikipedia’s list of fake news websites and Wikidata’s list of news websites.
Notably, Peter said that as of now the tool does not add user-inputted domains to the database. So if you’re searching using a set of domains that you consider sensitive, you can take some solace in the fact that the tool will not add your site(s) to the Information Laundromat dataset.
Ranking Technical Website Indicators
As noted above, it’s critical to understand the relative strengths and weaknesses of site indicators surfaced by the tool. Otherwise you risk overstating the connection between sites. Fortunately, the Information Laundromat’s documentation offers a useful breakdown of indicators.
For example, it’s a weak connection if multiple sites use WordPress as their content management system. Hundreds of millions of websites use WordPress; it’s not a useful signal on its own to connect sites together. But the connection between sites is much stronger if they all use the same Google AdSense code.
Ideally, you want to identify multiple technical indicators that connect a set of sites, and to combine that with other information to properly assess the strength of the connections.
To aid with analysis, the Information Laundromat has sorted indicators into three tiers. The results page helpfully uses color coding to point you towards strong, moderate, or weak indicators. You still need to perform your own analysis, but it’s a useful starting point.
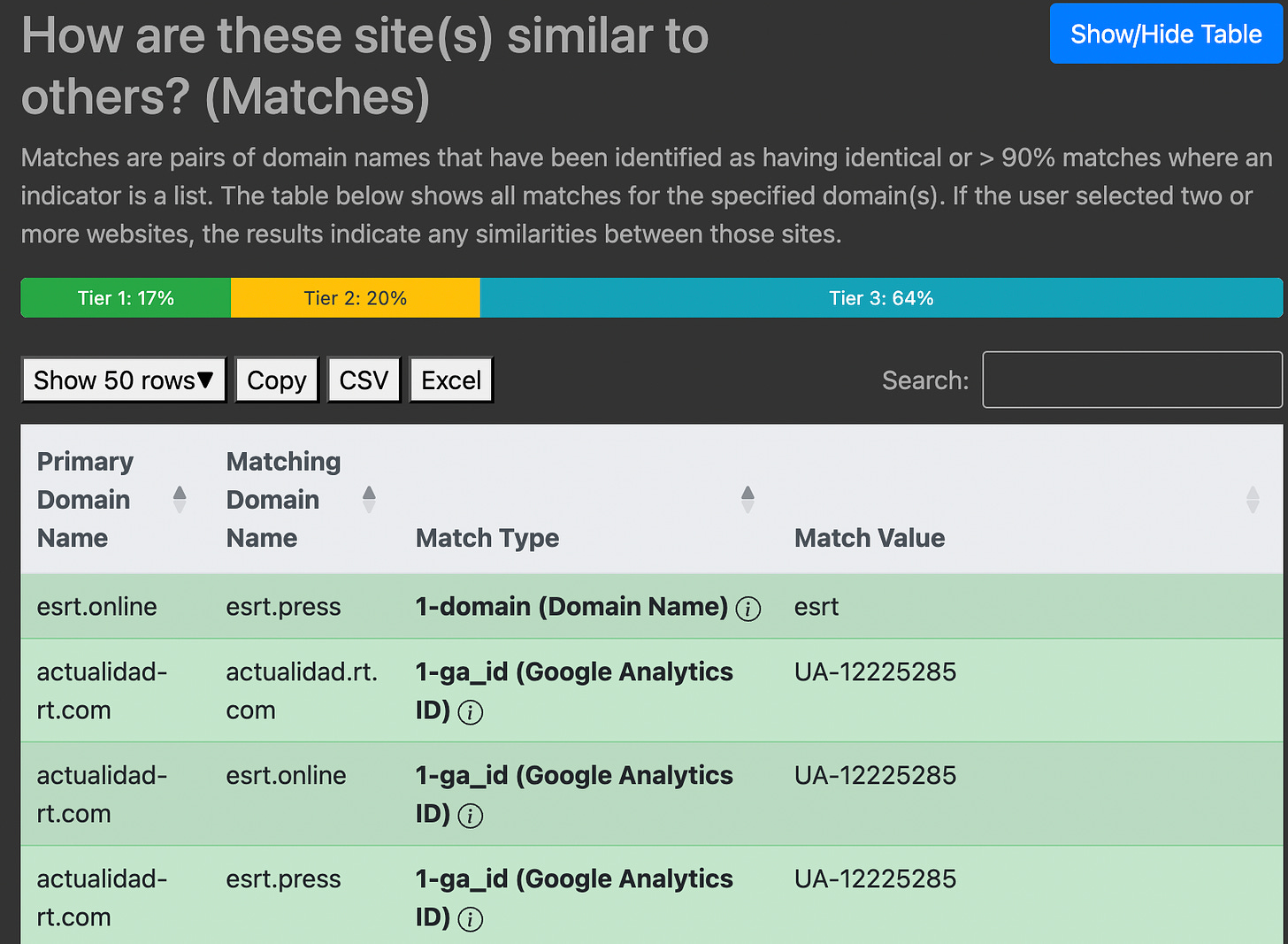
A sample metadata search run using RT-related domains. Image: Screenshot, Digital Investigations
Here are the three indicator tiers from the Information Laundromat’s documentation.
-
- Tier 1: These “are typically unique or highly indicative of the provenance of a website” and includes “unique IDs for verification purposes and web services like Google, Yandex, etc as well as site metadata like WHOIS information and certification.”
- Tier 2: Such indicators “offer a moderate level of certainty regarding the provenance of a website.” They “provide valuable context” and include “IPs within the same subnet, matching meta tags, and commonalities in standard and custom response headers.”
- Tier 3: They suggest using these indicators in combination with higher-tier indicators. Tier 3 includes “shared CSS classes, UUIDs, and Content Management Systems.”
Editor’s Note: This post was originally published on ProPublica reporter Craig Silverman’s Digital Investigations Substack and is reprinted here with permission.
 Craig Silverman is a national reporter for ProPublica, covering voting, platforms, disinformation, and online manipulation. He was previously media editor of BuzzFeed News, where he pioneered coverage of digital disinformation.
Craig Silverman is a national reporter for ProPublica, covering voting, platforms, disinformation, and online manipulation. He was previously media editor of BuzzFeed News, where he pioneered coverage of digital disinformation.

